When the Nation Clicked Play at the Same Time
The System Design That Could Have Saved Toffee and Bioscope
Disclaimer: Everything in this article, such as traffic numbers, failure modes, and architectural gaps is my own speculation, educated I hope but speculation nonetheless. I was a viewer that night, not an engineer on either team. My reconstruction draws from public engineering talks, industry-standard streaming architecture, and documented practices from teams like JioCinema, Hotstar, and Netflix. The patterns are real; their application to Toffee and Bioscope specifically is not. If anyone from either team spots an error, I'd love to hear it.
The Night Everything Broke
It was supposed to be the night Bangladeshi football fans got exactly what they were promised. The FIFA World Cup opening ceremony was approaching, and the excitement across Bangladesh was high as usual. For weeks, Toffee and Bioscope had painted billboards, social media feeds, and TV spots promising flawless HD live streaming. It worked. Millions of fans bought their 99 Taka subscriptions days in advance and gathered around their phones and TVs at the exact same moment.
Then the infrastructure collapsed.
First, the paywalls suffered. Digital wallets hung on "Processing..." and ended in cryptic error codes. I stared at my own screen in disbelief. I quickly opened WhatsApp and texted my friend: "Tor ki obostha? Tor ki app choltese?"
His reply came instantly: "Nah, akhon OTP-i ashtese na re bhai!"
The One-Time Passwords (OTPs) had vanished into a digital void, SMS gateways completely choked by the sudden spike in verification requests. And for the lucky few who miraculously bypassed the payment and login hurdles? Their reward was a mocking, infinite buffer. The video simply would not load. Social media turned into a wall of furious complaints. The platforms' servers weren't just struggling but they were slowly collapsing.
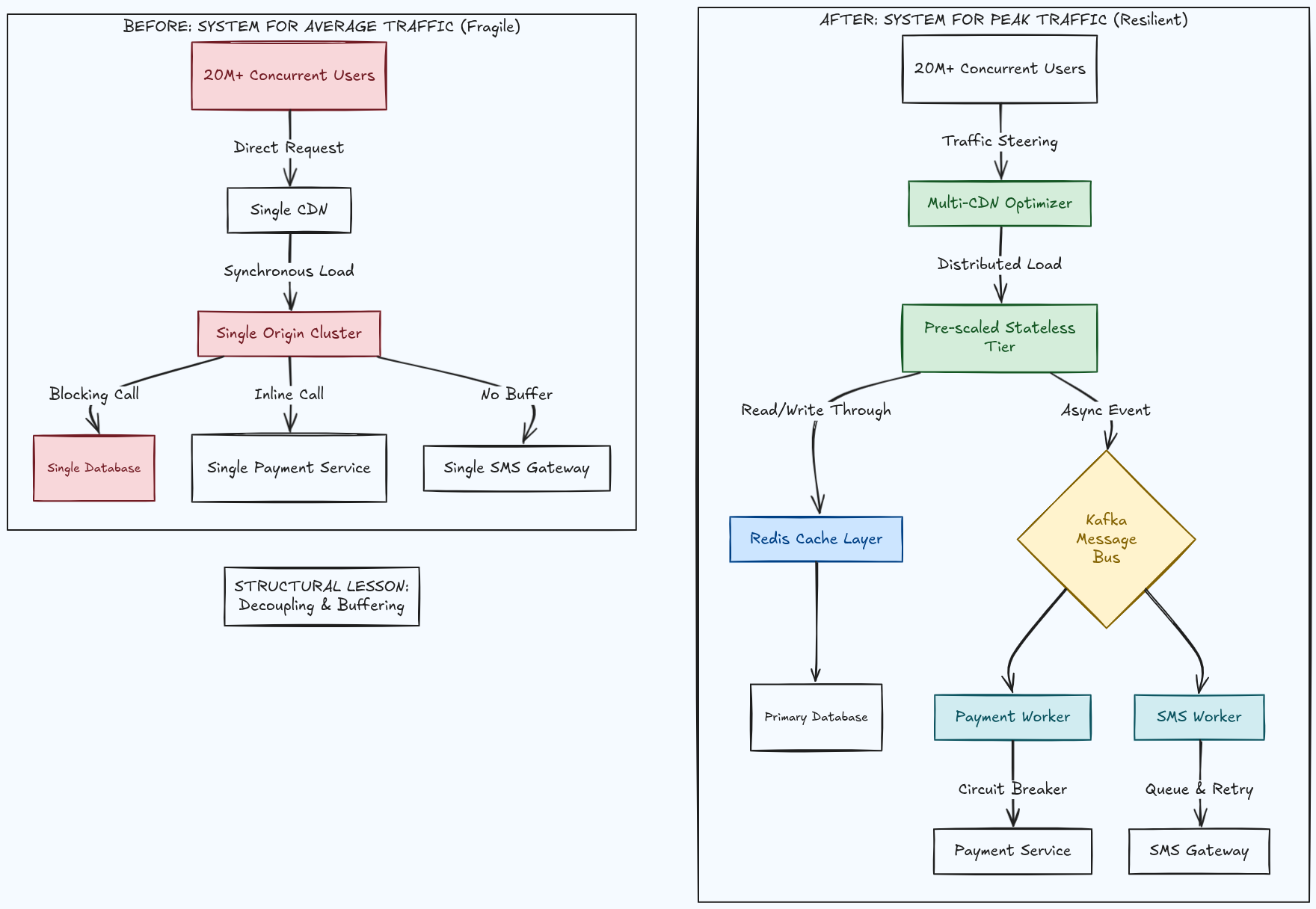
This is not a story about a bad product. Toffee and Bioscope are serious platforms with real engineering teams, backed by the immense infrastructure and resources of telecom giants Banglalink and Grameenphone.
This is a story about the systems, the patterns, and the architectural decisions that could have changed the outcome entirely.
Live Streaming Is A Different Ball Game
First, we need to understand why live sports streaming is different from regular streaming.
Netflix pre-position popular content on their own CDN appliances (check out OpenConnect by Netflix) inside ISP data centers before anyone watches. When you hit play, the file is already sitting on a server in your city. The CDN cache hit rate approaches almost 100%.
Live sports breaks the assumption that makes this work.
There is no file to pre-position—the content is being created in real time. There is no "watch it later" distribution. When a FIFA match kicks off, the gentle spread of traffic collapses to near-zero width. Traffic is not distributed across hours but is concentrated into seconds.
Imagine a platform built for 50,000 concurrent users on a weekday evening. A major FIFA match might bring 2,000,000—a 40× spike—as everyone tunes in at once.
And a live viewer is not passive. Their player is constantly asking "what's next?", fetching the playlist of upcoming video chunks, playing each chunk, refreshing ads. Every viewer triggers a steady stream of requests, every second, for the entire match.
This is the fundamental challenge. Everything that follows is a consequence of it.
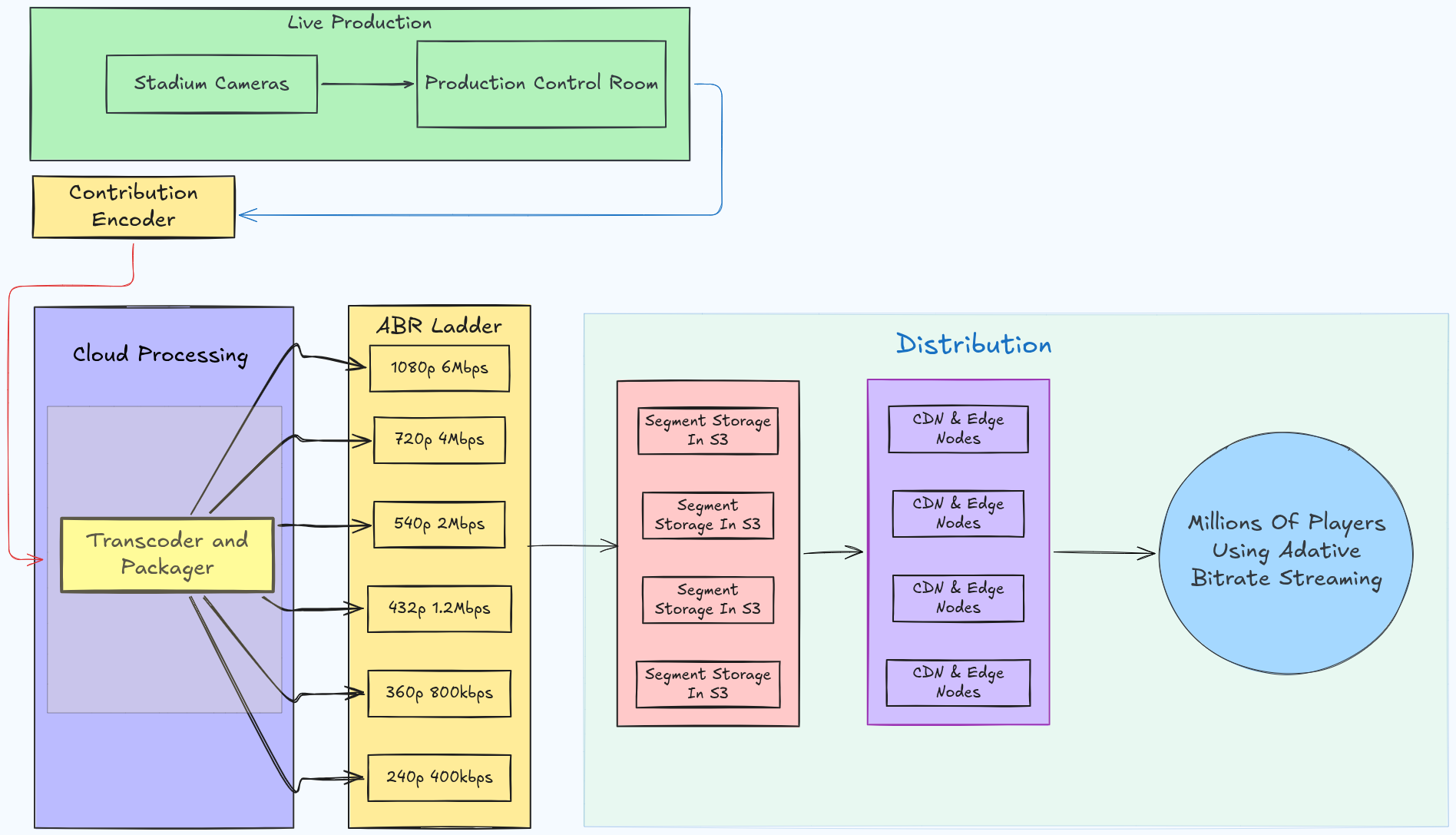
From Stadium to Screen: The Live Video Pipeline
But first, how does a broadcast travel from stadium cameras to a smartphone in Dhaka? Understanding this pipeline is essential, and it is where the engineering challenges actually live.
The camera feeds flow into a Production Control Room, where broadcast engineers mix multiple angles and produce the clean broadcast signal. This travels to a contribution encoder, which compresses the massive raw feed into something manageable.
The contribution encoder feeds to distribution transcoders, which take that single compressed stream and produce a family of output variants—typically 6 to 8 quality levels—from 240p at 300 kbps for users on slow connections, all the way up to 1080p or even 4K for faster connections.
These variant streams are then cut into short segments which are typically 4 to 6 seconds of video per file by the packager, which formats them in either HLS (HTTP Live Streaming) or DASH (Dynamic Adaptive Streaming over HTTP). Both formats work on the same principle: video is delivered as a series of regular HTTP file downloads rather than a continuous data stream. This is what makes live video cacheable, distributable, and recoverable from failures.
Segments are pushed to object storage (think S3), then pulled by CDN edge nodes, and finally delivered to the player. The whole journey, from camera to phone screen, takes between 6 and 30 seconds depending on configuration, encoding speed, and CDN propagation.
The player's job is to pick the right variant in real time and keep picking as conditions change. This is Adaptive Bitrate Streaming (ABR): the video player continuously measures available bandwidth and buffer health, then switches between quality levels mid-stream, invisibly, without rebuffering. If your 4G signal weakens as you walk into a building, the player drops from 720p to 360p at the next segment boundary. Signal recovers, it climbs back up.
From Camera to Phone: The Live Streaming Pipeline
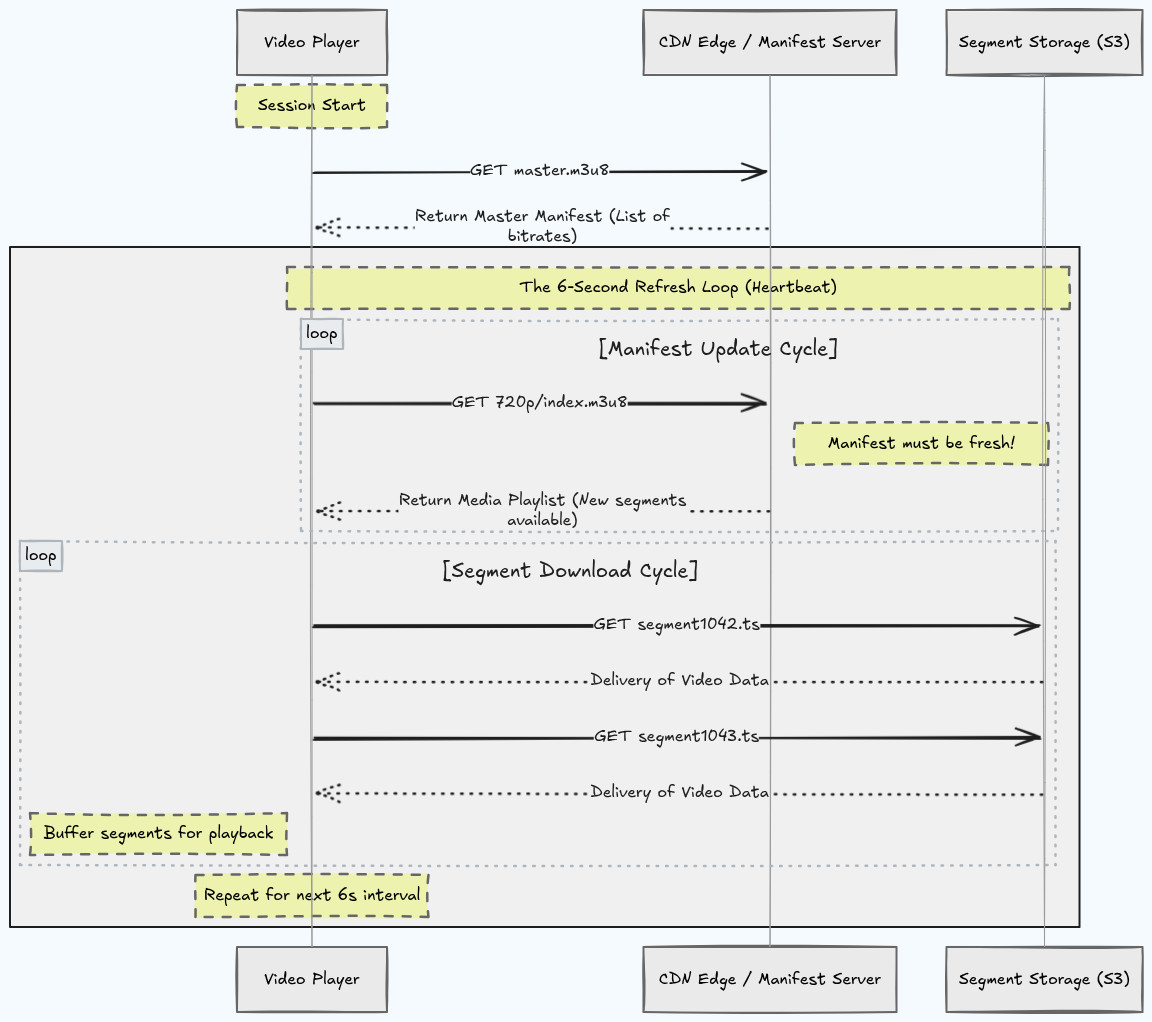
The Manifest Bottleneck
This is the technical heart of why platforms fail at scale. Bear with the mechanics; they explain everything.
When your video player starts up, its first action is to fetch a master manifest, a tiny text file (master.m3u8) listing the available quality levels:
#EXTM3U
#EXT-X-STREAM-INF:BANDWIDTH=300000,RESOLUTION=426x240
240p/index.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=800000,RESOLUTION=854x480
480p/index.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=3000000,RESOLUTION=1280x720
720p/index.m3u8
The player picks a quality level based on current network conditions and fetches the corresponding child manifest—another tiny text file listing the actual video segments to download:
#EXTM3U
#EXT-X-TARGETDURATION:6
#EXT-X-MEDIA-SEQUENCE:1042
segment1042.ts
segment1043.ts
segment1044.ts
The player downloads these segments, buffers them, plays them, and then re-fetches the child manifest to discover the next segments. It does this continuously, every 4 to 6 seconds, for the entire duration of the match.
Every player is constantly asking the manifest: "What's next?"
Now the math. A typical viewer polls the child manifest roughly every 6 seconds. With 2,000,000 concurrent viewers, that's:
2,000,000 ÷ 6 ≈ 333,000 manifest requests per second
But the platform serves 6 quality tiers (240p, 360p, 480p, 720p, 1080p, audio-only), each with its own manifest URL. Each tier generates its own 333,000 RPS:
333,000 × 6 tiers ≈ 2,000,000 manifest requests per second
This is exactly why CDN edge caching must absorb this load. But caching a live manifest introduces a trap.
What Your Video Player Is Actually Doing Every 6 Seconds
The TTL Trap
TTL (Time To Live) is how long a CDN is allowed to serve a cached copy before checking origin for a fresh one. For static content like images, TTL is easy: set it to your desired time and forget about it. For a live manifest, TTL is a trap.
- Set TTL too long → viewers fall behind the live broadcast. Their player follows a stale manifest and sees segments from 30 seconds ago. Your friend's "GOAL!" text arrives before you see it on screen.
- Set TTL too short → the cache barely helps. Every CDN node across the country phones home to origin every 2 seconds. The origin is hammered constantly, all at once.
Think of it like a restaurant. Too long a TTL is keeping yesterday's menu on the table, so customers order dishes you no longer have. Too short a TTL is running to the chef every time someone asks "what's today's special?", so the chef gets overwhelmed. You need the menu fresh enough without swamping the kitchen.
The fix is three techniques working together:
- Split cache headers. Cache at the CDN for one segment duration (4–6s), but tell the player
no-cache. The player always checks the CDN; the CDN only checks origin every few seconds. - Stale-while-revalidate. Serve the expired manifest immediately, fetch a fresh one in the background. The player never waits.
- Pre-push manifests. The packager pushes each new manifest to the CDN the moment it is created. The CDN is always fresh before anyone asks.
Ashutosh Agrawal, who architected the system behind 32 million concurrent IPL streams at Jio, identifies this TTL tuning as the most critical and under-appreciated challenge in live streaming. Balancing cache hit rate with freshness requires live monitoring and real-time adjustments during events, not a config you set once and forget.
CDN Architecture and the Thundering Herd
The Single-CDN Problem
Even with a perfectly tuned manifest strategy, video segments must reach millions of devices across Bangladesh's diverse network—including fast urban fiber, congested city 4G, rural 3G, and everything in between.
A single CDN provider, no matter how large, has regional strengths and weaknesses. During a major event, it can become oversubscribed in specific regions, causing quality degradation that appears invisible from the origin; everything looks healthy at origin, but users in Chittagong are buffering because the last-mile CDN nodes there are saturated.
The answer is obviously Multi-CDN: a routing layer that continuously measures latency, throughput, error rates, and capacity utilization across multiple CDN providers, and resolves each viewer's DNS request to whichever CDN is currently best positioned to serve them. If CDN-A's Dhaka nodes are overloaded, new users are silently shifted to CDN-B, with no manual intervention and no downtime.
When tens of millions of viewers tune in simultaneously for an IPL match, JioHotstar's infrastructure manages record-breaking concurrent viewership spikes through a combination of predictive Multi-CDN load balancing and strategically positioned edge nodes.
At the core of this is a multi-layered streaming stack built for scale. Video chunks are distributed simultaneously across multiple CDN partners including Akamai, AWS CloudFront, and Cloudflare so that no single provider becomes a bottleneck and failovers happen instantly if one struggles under load. User requests are then resolved through intelligent DNS and anycast routing, directing each viewer to the nearest healthy CDN, whether that's in Delhi, Mumbai, or Bangalore, rather than funneling everyone through a central server. Edge caching takes this a step further: when 200,000 people in the same city request the same video segment, the origin server only has to serve it once, and after that it's delivered locally from the edge.
The Thundering Herd
CDN architecture alone doesn't solve what happens when the cache itself fails. This is the thundering herd problem, and it's one of the most dangerous failure modes in live streaming. This is exactly what I assume happened when everyone wanted to watch the opening ceremony.
In normal conditions, a CDN cache absorbs the vast majority of requests. But when a cache entry expires, or was never populated, all simultaneous requests for that resource fall through to the origin at once. The origin receives a wall of identical requests and collapses trying to answer them.
For a streaming platform, thundering herds appear in several places:
- Millions of users open the app simultaneously and hit the authentication service
- Millions of players all request the master manifest the moment the stream goes live
- At halftime, everyone steps away for tea and returns two minutes later, creating a second synchronized spike
- A push notification sent to 10 million users causes them all to open the app within 30 seconds
How a Cache Miss Becomes a Database Killer
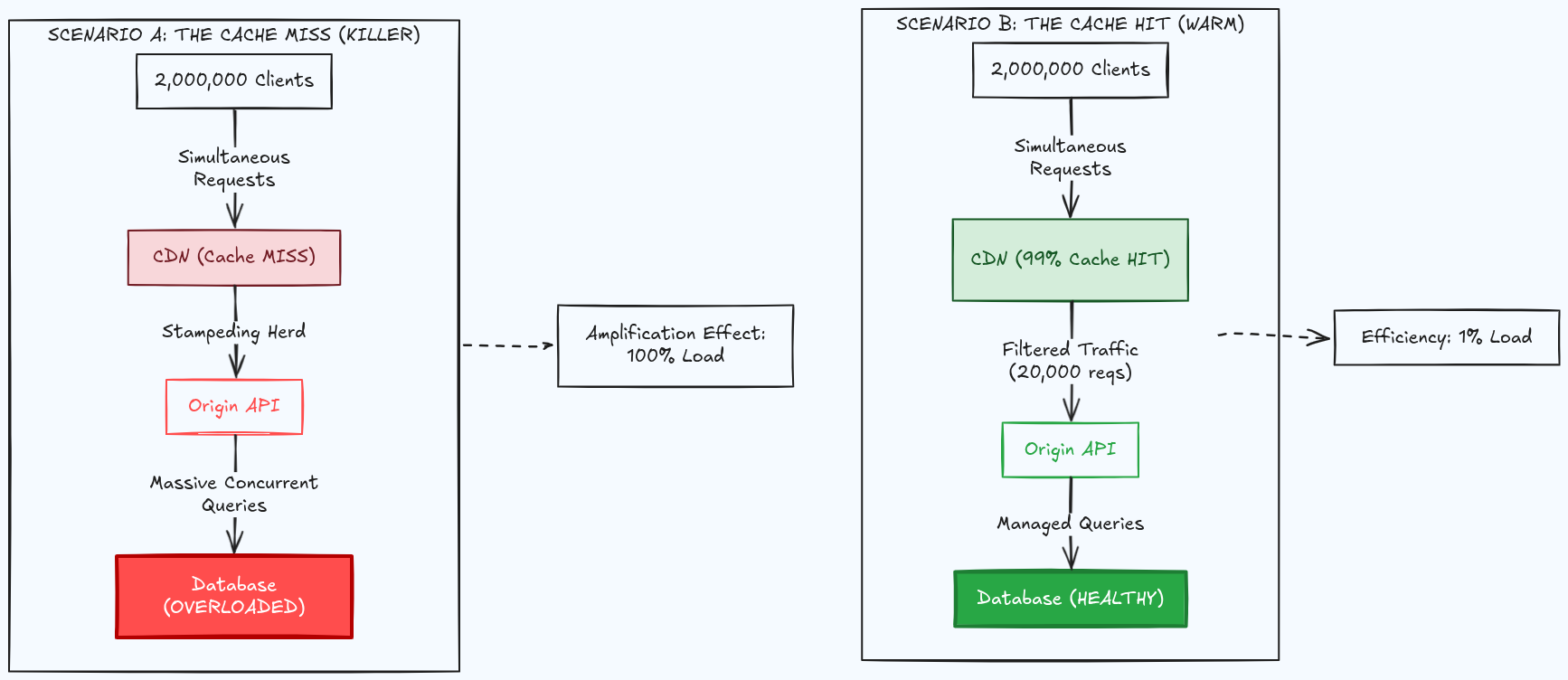
Architectural solutions:
Request coalescing. The cache layer holds duplicate in-flight requests in a queue and serves them all from a single backend fetch. Nginx and other platforms can do this transparently. Instead of 50,000 parallel requests to origin, there is one, and all 50,000 clients receive the response.
Cache warming. Before the match begins, pre-generate and pre-load critical resources (master manifests, authentication token templates, API responses for the match metadata) into the CDN cache. The first million users find a warm cache waiting, not a cold miss.
Exponential backoff with jitter. When a request fails, clients must not all retry at the same instant. Adding jitter (e.g. 500ms ± 300ms instead of exactly 500ms) breaks the synchronization. Combined with exponential backoff (1s, 2s, 4s, 8s, ...), clients give the struggling backend progressively more breathing room. It's the AWS Architecture Blog and Google SRE Workbook's non-negotiable primitive for any client talking to an overloadable service, and especially critical at halftime: clients whose streams briefly failed should not all reconnect at once and recreate the stampede.
Pre-Scale or Perish: Why Autoscaling Fails at Kickoff
The Provisioning Gap
The natural engineering response to traffic spikes is autoscaling: when CPU exceeds 70%, spin up more servers. Cloud providers have made this deceptively easy. But for live sports, autoscaling is the wrong tool.
The problem is time. Provisioning a new cloud server, even in a modern environment, takes 3 to 30 minutes. The VM must launch, pull the application image, run startup scripts, register with the load balancer, and pass health checks before the first real request arrives. During a FIFA kickoff, 3 minutes is an eternity. By the time new servers are ready, the cascade has already begun.
Gaurav Kamboj, Cloud Architect at Hotstar, made this precise: standard CPU-based autoscaling is fundamentally the wrong tool for live streaming. It reacts to a crisis already in progress rather than anticipating one about to begin.
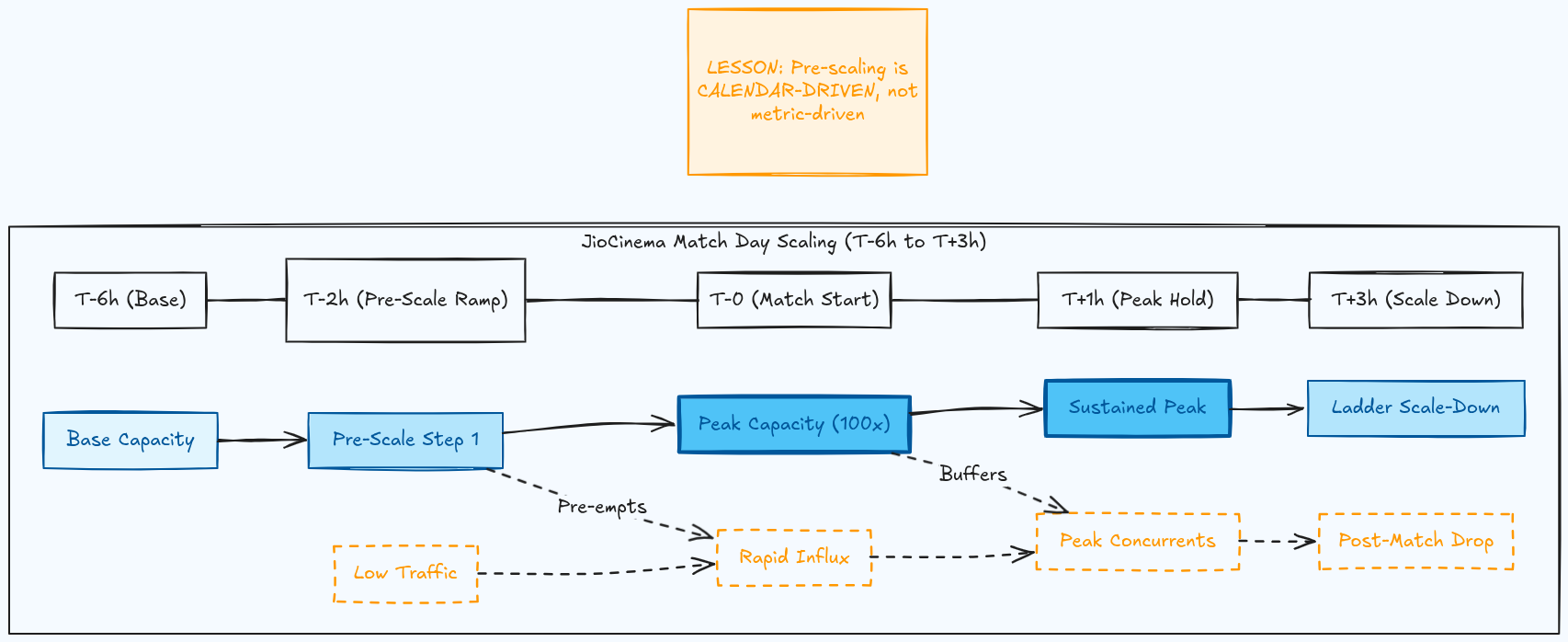
The Solution: Pre-Scale Based on Calendars, Not Metrics
Serious live streaming platforms provision infrastructure proactively, hours before a match begins. They know the match schedule. They know historical concurrency peaks from similar events. They scale to expected peak capacity before a single viewer shows up, then scale back down after the event.
JioCinema replaced CPU-based triggers with custom domain-relevant signals: request rates and active connection counts per server, which are metrics that correlate directly with streaming load rather than lagging behind it.
The only reliable way to validate capacity estimates is load testing before the event: fire synthetic traffic equivalent to expected peak (or 2× peak) at your full infrastructure, and find the breaking points. This is not optional at scale. It is the only way to discover bottlenecks before 20 million real viewers discover them first.
Before every major IPL season, JioCinema ran "game day" exercises, blasting synthetic traffic at the production system without warning the on-call engineers. These tests validated not just whether the system could handle the load, but whether the engineering team could see the problem, diagnose it, and respond within acceptable timeframes. An observability system that works at normal load often produces overwhelming noise during a major incident—game days are the only way to find this out before match night.
The cost tradeoff is real. Pre-scaling to peak capacity means paying for servers that are idle for most of the day. For a platform that hosts a major event once every few months, this is expensive.
How JioCinema Scales Before the Match Begins
What Could Have Saved Toffee and Bioscope
Let's make this concrete. What would the architecture of a Toffee or Bioscope prepared for a major FIFA event actually look like?
Few months before the event. The engineering team estimates expected peak concurrent users based on historical data, match significance, and app download trends. They run full-scale load tests in a production-equivalent environment, specifically designed to find breaking points. They identify the top five failure modes and build mitigations for each.
One month before. Feature flags are implemented across every non-critical feature. The team agrees on explicit degradation criteria: "If error rate exceeds 2%, disable comments. If it exceeds 5%, disable recommendations. If it exceeds 10%, enable Panic Mode." Panic Mode means the application tier is pre-configured to serve static, pre-computed API responses, which are cached at the CDN edge, bypassing dynamic backend logic entirely. Users continue receiving content and the app continues to function even if the backend is struggling. Pre-computed static responses are prepared for the most critical endpoints.
One week before. CDN configuration is audited. Manifest TTLs are validated against segment duration. Multi-CDN routing policies are tested. The on-call rotation is confirmed, with experienced engineers available for the match duration plus two hours on each side.
Six to eight hours before kickoff. Infrastructure pre-scaling begins. The server fleet is brought to estimated peak capacity. Cache warming scripts pre-populate critical data: content metadata, subscription status for the most active users. The stream pipeline is started and validated end-to-end with internal test streams.
One hour before. The team is in a dedicated incident response channel. Dashboards are live. Alert thresholds have been temporarily tightened. A war room call connects on-call engineers, infrastructure team, CDN account representatives, and business stakeholders.
Kickoff. Traffic arrives in a wave. The pre-scaled fleet handles the initial surge without triggering any autoscaling events. The warmed CDN serves manifest requests from cache. Request coalescing absorbs the thundering herd on the few resources that weren't pre-warmed. Kafka queues absorb the burst of analytics events without touching the database. Non-critical services sit behind circuit breakers; if recommendations or the view counter struggles, the video stream is unaffected.
Halftime. Traffic dips, then surges again as users return. The platform handles the re-surge identically to kickoff.
After the final whistle. Infrastructure scales down in increments of 10% every 15 minutes, supporting users staying for highlights and post-match analysis. Total traffic returns to baseline 45 minutes later.
This is not a fantasy. It is exactly the approach that made JioCinema's IPL streams successful at 20 million concurrent devices.
The Cost Question
There's an honest conversation to be had here. Multi-CDN, pre-scaled fleets, Redis clusters, sophisticated observability, this is not cheap.
But consider the alternative. A single catastrophic outage during a major FIFA match carries enormous costs: subscriber churn from users who experienced the failure, reputational damage amplified instantly by social media, lost advertising revenue from ads that were never served.
So How Did Other Platforms Scale?
The Multi-CDN Optimizer
JioCinema doesn't pick a CDN and trust it. They run a real-time optimizer that continuously measures latency, throughput, and error rates across multiple CDN providers simultaneously. Every DNS resolution routes a viewer to whichever CDN is performing best right now for their location. When Akamai's Mumbai nodes saturate during peak IPL, viewers shift silently to Fastly or CloudFront. No alert fires. No engineer intervenes. The routing layer handles it automatically. CDNs are not commodities. Their performance is highly geography-dependent and changes in real time under load.
Kafka
During peak IPL, JioCinema processes millions of events per second: view session starts, segment requests, ad impressions, quality switches, heartbeats. None of these touch a database synchronously.
Every non-critical data path publishes to Kafka topics. Separate consumer processes drain those queues at their own pace and write to the analytics store. The application server that handled your session start returned a response in under 5ms; it didn't wait for a database write. If the analytics database slows down, events queue in Kafka rather than blocking the user-facing request. The user experience is completely isolated from backend data pipeline health.
This is also how the "32M concurrent viewers" number gets computed in real time and displayed on screen. View events stream into Kafka, a streaming aggregator increments a counter, and the CDN serves the updated count. The count lags by a few seconds, which is entirely acceptable, rather than blocking on a database read-modify-write at 32 million QPS, which would be catastrophic.
Redis and Panic Mode
JioCinema's Redis layer caches everything that changes slowly: content metadata, stream URLs, subscription status, ad targeting profiles. During an IPL match, the database is rarely touched for the data that matters most. Nearly all reads are served from in-memory cache.
Panic Mode is the extreme version of this. Before every major match, JioCinema snapshots the expected API responses for the most critical endpoints—namely "what is the stream URL for IPL Match 42?" and "is user X subscribed?"—and stores them as static JSON. If the backend databases become overwhelmed during the event, a single flag flips and the CDN begins serving these pre-computed static responses instead of dynamic API calls. The live experience is preserved even while the dynamic infrastructure beneath it is struggling.
It's a blunt instrument. Users might briefly see a cached subscription status that is slightly stale. But they will not see a loading spinner instead of cricket. For a live sports platform, that is the correct tradeoff.
Custom Autoscaling Metrics
JioCinema doesn't scale on CPU. They scale on active connection counts and request rates per server—signals that correlate directly with streaming load and respond in seconds rather than minutes. Combined with aggressive pre-scaling based on match schedules, their fleet is at peak capacity before the first ball is bowled.
The result: during IPL 2023, no significant autoscaling event fired during the match. The system was already where it needed to be.
Miscellaneous
An interesting scenario I learnt from the articles was the importance of external and internal factors in increasing the traffic peak. External factors can be the sudden rise in the concurrent traffic due to the batting of a popular cricketer (MS Dhoni, Virat Kohli) and the sudden dip when they get out.
This can also be viewed from a different perspective—as when they get out, the sudden dip in the video streaming service increases the traffic on the home page. Thus, the home page APIs should also be ready to handle such traffic.
Conclusion
Millions of Bangladeshis watching football is a difficult engineering problem. Toffee and Bioscope will get another chance. The next world cup, the next Bangladesh ODI, and the next moment when millions of people open an app at the same second. The question is whether the architecture waiting for them on that day will be the same one that failed.
Sources: Engineering practices in this series draw on publicly shared insights from Prachi Sharma (Senior Engineering Director, JioCinema), Gaurav Kamboj (Cloud Architect, Hotstar), and Ashutosh Agrawal (software architect, 32M concurrent stream system), combined with public network data on Bangladeshi mobile infrastructure and industry-standard streaming engineering practices.